Collatz@Home: a distributed computing system powered by WebGPU
WebGPU is a cross-platform graphics API supported by most major browsers and operating systems. It was started in 2021 and has keen attracted interest from major tech companies such as Microsoft and Apple (other tech companies are available). Perhaps most notably about WebGPU it is able to run in-browser with efficiency comparable to native GPU applications.
As a Christmas treat I thought I’d write a tutorial that I haven’t seen elsewhere. Folding@home is a project that lets individuals ‘donate’ their compute to science and medicine. The idea is that you may download the program and run it, letting your computer process parts of protein folding simulations that that aid scientific research and contributes to medicine. My idea is to create a similar distributed computing application that needs only an open browser tab to contribute. Protein folding is a huge challenge that I don’t mean to take on myself so instead I picked a nice simple one that suits the style of my blog.
The Collatz conjecture is as follows:
$$ T(n)= \begin{cases} \frac{n}{2}, & n\equiv 0 \pmod 2,\\[6pt] 3n+1, & n\equiv 1 \pmod 2. \end{cases} $$Starting from any positive integer $n$ the conjecture states that repeatedly applying $T$ will eventually produce the value 1. Despite its simple definition and extensive computational verification, the conjecture has neither been proven nor disproven.
It’s not certain how many numbers have been tested but this paper published May 2025 in the ‘Journal of Supercomputing’ says the conjecture holds at least up to $2^{71}$
While its not likely that we will disprove the conjecture it’s worth a shot and is a good substitute for protein folding for the purposes of what we are trying to learn. We can also gather up some statistics that may help other mathematicians attempt proofs themselves.
Computation on the CPU
This is what the function looks like in Rust. Note that I have chosen to use unsigned 128 bit integers (u128) because we’re aiming to compute numbers higher than the previous limit of $2^{71}$
fn collatz(mut n: u128) -> (u128, u128) {
// count the number of steps we've done and highest number reached
let mut steps: u128 = 0;
let mut max = n;
// loop until we reach 1
while n != 1 {
if n % 2 == 0 {
// if n is even divide by 2
n = n / 2;
} else {
// if n is odd do 3n + 1
n = 3 * n + 1;
}
if n > max {
max = n;
}
steps += 1;
}
return (steps, max);
}
This function is only partially correct: If the conjecture is false we could enter a never-ending cycle without reaching 1. We can’t just keep a list of seen values to check for a cycle as this would be spatially inefficient (we also don’t have hash sets in the GPU). However we can use the ‘Tortoise and Hare algorithm’ where we have two variables:
- The Hare who moves every iteration
- The Tortoise who moves every other iteration
We can provably state that if the variables ever meet (have the same value) in an iteration then there must be a cycle, and if there is a cycle then the variables will meet. I’ll set the top bit of steps to 1 if there is a cycle.
fn collatz_step(n: u128) -> u128 {
if n % 2 == 0 {
n / 2
} else {
3 * n + 1
}
}
fn collatz(mut n: u128) -> (u128, u128) {
let mut steps: u128 = 0;
let mut max = n;
// Tortoise–hare setup
let mut tortoise = n;
let mut hare = collatz_step(n); // hare starts one step ahead or they have already met
while hare != 1 {
// hare moves every step
hare = collatz_step(hare);
// tortoise moves every other step
if steps % 2 == 0 {
tortoise = collatz_step(tortoise);
}
if hare > max {
max = hare;
}
steps += 1;
if hare == tortoise {
// top bit of steps represents a cycle
return (steps | 1 << 31, max);
}
}
(steps, max)
}
There are also possible issues with overflows but I’ll leave you to deal with these ;).
GPU is tricky
To do an equivalent function in WGSL we have to take a few more steps. The full code is at the bottom of this section.
Unsigned 128 bit integers
WGSL doesn’t have u128s as native so we can build it up from an array of 4 u32s (and a couple helpful constants):
struct U128 {
parts: array<u32, 4> // [least significant, ..., ..., most significant]
}
const ZERO_U128 = U128(array<u32, 4>(0u, 0u, 0u, 0u));
const ONE_U128 = U128(array<u32, 4>(1u, 0u, 0u, 0u));
We can also define a few specific functions for mangling the data
fn is_one(n: U128) -> bool {
return n.parts[0] == 1u && n.parts[1] == 0u && n.parts[2] == 0u && n.parts[3] == 0u;
}
fn is_even(n: U128) -> bool {
return (n.parts[0] & 1u) == 0u;
}
fn div_by_2(n: U128) -> U128 {
var result: U128;
// right shift by 1 and get the bottom of the most significant one
// we don't care about we don’t care about overflows or underflows (there will never be any)
result.parts[0] = (n.parts[0] >> 1u) | ((n.parts[1] & 1u) << 31u);
result.parts[1] = (n.parts[1] >> 1u) | ((n.parts[2] & 1u) << 31u);
result.parts[2] = (n.parts[2] >> 1u) | ((n.parts[3] & 1u) << 31u);
result.parts[3] = n.parts[3] >> 1u;
return result;
}
// Check if two U128 values are equal
fn equals(a: U128, b: U128) -> bool {
return a.parts[0] == b.parts[0] && a.parts[1] == b.parts[1] &&
a.parts[2] == b.parts[2] && a.parts[3] == b.parts[3];
}
fn greater_than(a: U128, b: U128) -> bool {
if (a.parts[3] != b.parts[3]) { return a.parts[3] > b.parts[3]; }
if (a.parts[2] != b.parts[2]) { return a.parts[2] > b.parts[2]; }
if (a.parts[1] != b.parts[1]) { return a.parts[1] > b.parts[1]; }
return a.parts[0] > b.parts[0];
}
Here we have helpers to check if a u128 is even or 1 as well as dividing a u128 by 2. When we get to addition and multiplication however, we have to be more careful about overflowing. In WGSL u32 addition overflows cause defined wraparound behaviour. This isn’t what we want so we will have to detect an overflow has occurred and return a result that tells us this. It would also be nice to have something that tells us if we did detect a cycle.
Overflow Handling
struct U128AddResult {
value: U128,
carry: u32, // 1 if overflowed past 128 bits
};
This is a bit of a hacky way to do it but it does the job so that’s what you get. We now have u128 addition with carry like so:
fn add_u128(a: U128, b: U128) -> U128AddResult {
var total: U128;
var res: U128AddResult;
var carry = 0u;
// add the parts
let sum0 = a.parts[0] + b.parts[0];
total.parts[0] = sum0;
// cool carry checking trick if it wraps around the sum will always be smaller than either of the parts
carry = u32(sum0 < a.parts[0]);
let sum1 = a.parts[1] + b.parts[1] + carry;
total.parts[1] = sum1;
carry = u32(sum1 < a.parts[1] || (carry == 1u && sum1 == a.parts[1]));
let sum2 = a.parts[2] + b.parts[2] + carry;
total.parts[2] = sum2;
carry = u32(sum2 < a.parts[2] || (carry == 1u && sum2 == a.parts[2]));
let sum3 = a.parts[3] + b.parts[3] + carry;
total.parts[3] = sum3;
carry = u32(sum3 < a.parts[3] || (carry == 1u && sum3 == a.parts[3]));
res.value=total;
res.carry=carry;
return res;
}
This will return the result of the operation, and whether it overflowed. For multiplication by 3 we can just do additions to itself, multiplication would be hard to program and likely much slower than just doing a small number of addition operations. I haven’t tested this however and it might be that doing a left shift operation by 1 and then adding is faster.
fn mul_3_add_1(n: U128) -> U128AddResult {
let doubled = add_u128(n, n);
if doubled.carry == 1u {
return doubled;
}
let tripled = add_u128(doubled.value, n);
if tripled.carry == 1u {
return tripled;
}
var one: U128;
one.parts[0] = 1u;
one.parts[1] = 0u;
one.parts[2] = 0u;
one.parts[3] = 0u;
let result = add_u128(tripled.value, one);
return result;
}
Put it all together
Special Return Values
| Field / Structure | Meaning | Notes / Flags |
|---|---|---|
U128AddResult.carry |
Indicates overflow during a u128 operation |
1 if overflow occurred |
CollatzResult.steps |
Number of iterations to reach 1 | Top bit set = cycle detected; lower 31 bits = step count |
CollatzResult.max |
Maximum value encountered in the sequence | Set to 0 if overflow occured |
| Cycle Flag | Top bit of steps in CollatzResult |
If set, a cycle was detected before reaching 1 |
struct CollatzResult {
steps: u32,
max: U128,
}
fn collatz(n_input: U128) -> CollatzResult {
var n = n_input;
var steps = 0u;
var max = n;
var tortoise = n;
var tortoise_steps = 0u;
var result: CollatzResult;
loop {
if (is_one(n)) {
break;
}
// Safety limit to prevent GPU hangs
if (steps >= 100000u) {
break;
}
if (is_even(n)) {
n = div_by_2(n);
} else {
let a = mul_3_add_1(n);
if a.carry == 1u {
result.steps = steps;
result.max = ZERO_U128;
return result;
}
n = a.value;
}
if (greater_than(n, max)) {
max = n;
}
steps++;
if (steps % 2u == 0u) {
if (is_even(tortoise)) {
tortoise = div_by_2(tortoise);
} else {
tortoise = mul_3_add_1(tortoise).value;
}
tortoise_steps++;
// check if we've found a cycle (tortoise meets hare)
if (equals(n, tortoise) && steps > 2u) {
// top bit of steps represents a cycle
steps = steps | (1u << 31u);
break;
}
}
}
result.steps = steps;
result.max = max;
return result;
}
This WGSL code will solve our problem but how do we actually pass the data between CPU and GPU?
Passing data between CPU and GPU
@group(0) @binding(0) var<storage, read> input: array<U128>;
@group(0) @binding(1) var<storage, read_write> output: array<CollatzResult>;
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) id: vec3<u32>) {
let idx = id.x;
if (idx < arrayLength(&input)) {
output[idx] = collatz(input[idx]);
}
}
We define bindings to specify our inputs and outputs.
@group(0) @binding(0) var<storage, read> input: array<u32>;
says ’there will be an input which is read-only and contains an array of u32s’
@group(0) @binding(1) var<storage, read_write> output: array<CollatzResult>;
says ’the output is an array of results, and is read-write’
@compute @workgroup_size(64)
says ’this is a compute shader entry point and 64 threads work together in a work group’
The code I have used is here:
struct U128 {
parts: array<u32, 4> // Little-endian: [low, mid_low, mid_high, high]
}
struct CollatzResult {
steps: u32,
max: U128,
}
struct U128AddResult {
value: U128,
carry: u32, // 1 if overflowed past 128 bits
};
@group(0) @binding(0) var<storage, read> input: array<U128>;
@group(0) @binding(1) var<storage, read_write> output: array<CollatzResult>;
const ZERO_U128 = U128(array<u32, 4>(0u, 0u, 0u, 0u));
const ONE_U128 = U128(array<u32, 4>(1u, 0u, 0u, 0u));
fn is_one(n: U128) -> bool {
return n.parts[0] == 1u && n.parts[1] == 0u && n.parts[2] == 0u && n.parts[3] == 0u;
}
fn is_even(n: U128) -> bool {
return (n.parts[0] & 1u) == 0u;
}
fn div_by_2(n: U128) -> U128 {
var result: U128;
// right shift by 1 and get the bottom of the highest one
result.parts[0] = (n.parts[0] >> 1u) | ((n.parts[1] & 1u) << 31u);
result.parts[1] = (n.parts[1] >> 1u) | ((n.parts[2] & 1u) << 31u);
result.parts[2] = (n.parts[2] >> 1u) | ((n.parts[3] & 1u) << 31u);
result.parts[3] = n.parts[3] >> 1u;
return result;
}
fn add_u128(a: U128, b: U128) -> U128AddResult {
var total: U128;
var res: U128AddResult;
var carry = 0u;
let sum0 = a.parts[0] + b.parts[0];
total.parts[0] = sum0;
carry = u32(sum0 < a.parts[0]);
let sum1 = a.parts[1] + b.parts[1] + carry;
total.parts[1] = sum1;
carry = u32(sum1 < a.parts[1] || (carry == 1u && sum1 == a.parts[1]));
let sum2 = a.parts[2] + b.parts[2] + carry;
total.parts[2] = sum2;
carry = u32(sum2 < a.parts[2] || (carry == 1u && sum2 == a.parts[2]));
let sum3 = a.parts[3] + b.parts[3] + carry;
total.parts[3] = sum3;
carry = u32(sum3 < a.parts[3] || (carry == 1u && sum3 == a.parts[3]));
res.value=total;
res.carry=carry;
return res;
}
fn mul_3_add_1(n: U128) -> U128AddResult {
let doubled = add_u128(n, n);
if doubled.carry == 1u {
return doubled;
}
let tripled = add_u128(doubled.value, n);
if tripled.carry == 1u {
return tripled;
}
let result = add_u128(tripled.value, ONE_U128);
return result;
}
fn greater_than(a: U128, b: U128) -> bool {
if (a.parts[3] != b.parts[3]) { return a.parts[3] > b.parts[3]; }
if (a.parts[2] != b.parts[2]) { return a.parts[2] > b.parts[2]; }
if (a.parts[1] != b.parts[1]) { return a.parts[1] > b.parts[1]; }
return a.parts[0] > b.parts[0];
}
fn equals(a: U128, b: U128) -> bool {
return a.parts[0] == b.parts[0] && a.parts[1] == b.parts[1] &&
a.parts[2] == b.parts[2] && a.parts[3] == b.parts[3];
}
fn collatz(n_input: U128) -> CollatzResult {
var n = n_input;
var steps = 0u;
var max = n;
var tortoise = n;
var tortoise_steps = 0u;
var result: CollatzResult;
loop {
if (is_one(n)) {
break;
}
// Safety limit to prevent GPU hangs
if (steps >= 100000u) {
break;
}
if (is_even(n)) {
n = div_by_2(n);
} else {
let a = mul_3_add_1(n);
if a.carry == 1u {
result.steps = steps;
result.max = ZERO_U128;
return result;
}
n = a.value;
}
if (greater_than(n, max)) {
max = n;
}
steps++;
if (steps % 2u == 0u) {
if (is_even(tortoise)) {
tortoise = div_by_2(tortoise);
} else {
tortoise = mul_3_add_1(tortoise).value;
}
tortoise_steps++;
// check if we've found a cycle (tortoise meets hare)
if (equals(n, tortoise) && steps > 2u) {
// Cycle detected, break out
// WE NEED SOME WAY TO RETURN CYCLE
break;
}
}
}
result.steps = steps;
result.max = max;
return result;
}
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) id: vec3<u32>) {
let idx = id.x;
if (idx < arrayLength(&input)) {
output[idx] = collatz(input[idx]);
}
}
Put this on the web
I’ve chosen to use Rust compiled to wasm to implement this, but you can use whatever you want. The code that I used is in this repository. I have an HTML button that runs this code on click. do_gpu_collatz calls my rust wasm function which then calls my WGSL code on the GPU and returns a list of u32s. I can then post this to my server to compile together the results.
runBtn.addEventListener('click', async () => {
const startN = document.getElementById('startN').value;
output.textContent = 'Running GPU Collatz...';
try {
let a = await do_gpu_collatz(startN);
const payload = { start: startN, results: a };
await fetch("/results", {
method: "POST",
headers: { "Content-Type": "application/json" },
// not sure if stringify is necessary
body: JSON.stringify(payload),
});
output.textContent = 'Done!';
} catch (e) {
output.textContent = 'Error: ' + e;
console.error(e);
}
});
Create a webserver
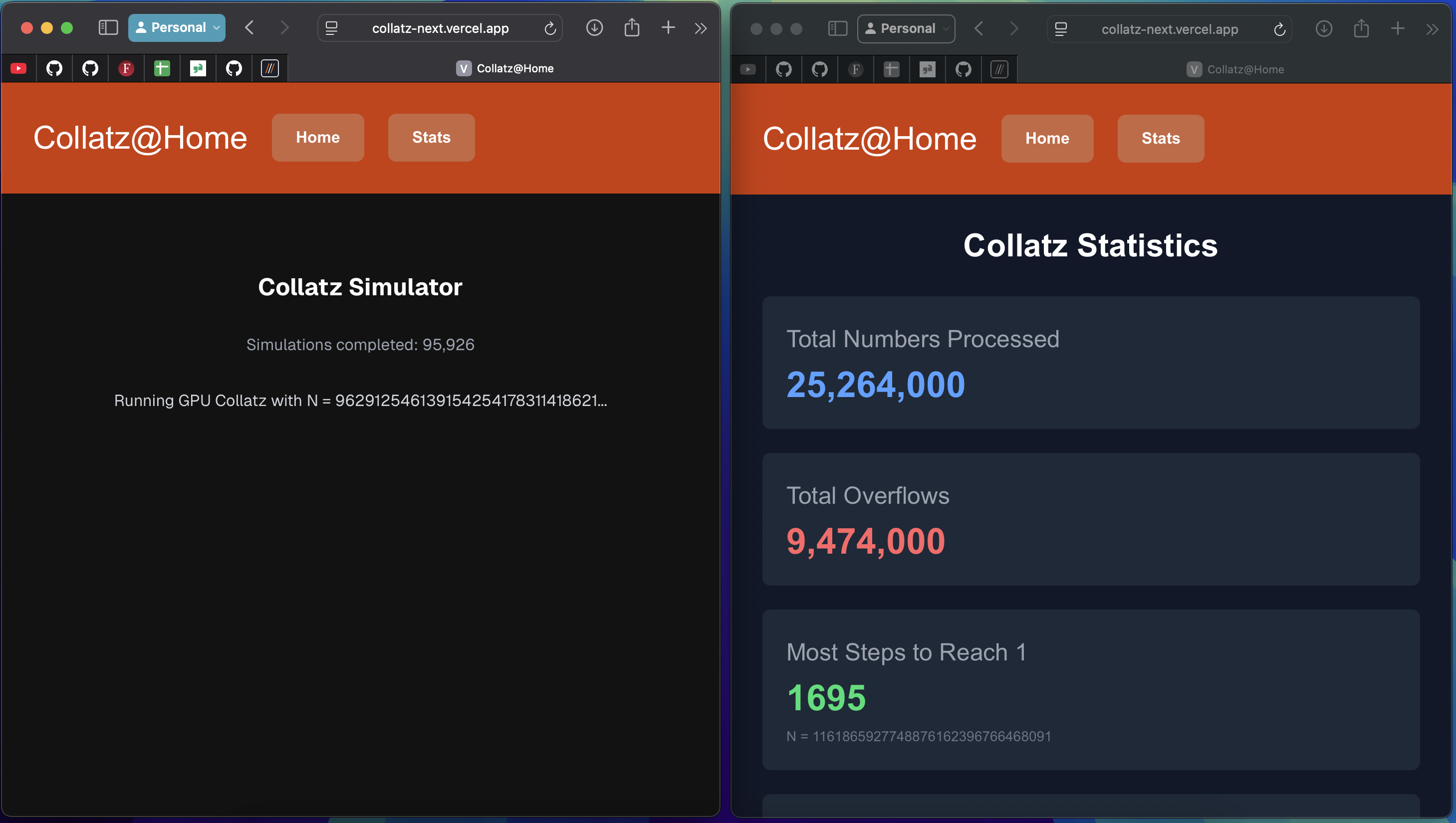
We are going to need a server to both serve the page that runs our code, and to receive the results of the computations. This would need a lot of storage as 50,000 simulations is about 1Mb. It would also be nice to have some kind of trust to fight against bad actors. I plan to assign computations in batches of 50k, and test validity by testing 4 random numbers in the batch. If any of their results don’t match mine, I can reject the whole batch. As this is just a tutorial I wont be storing anything permanently, but I will put up a leaderboard of top interesting numbers that have been found. The whole thing would take roughly 25,000,000,000,000,000,000 petabytes of data.
My version of this is hosted for free on Vercel who are limiting the number of api calls (link found here). I have severely limited the size of the batches to only 10,000, and added a timer to slow down the amount of post requests. Locally my laptop was able to process batches larger than 1,000,000 instantly and I believe with better infrastructure this would also work online.